
Omni-modal large language models (LLMs) are at the forefront of artificial intelligence research, seeking to unify multiple data modalities such as vision, language, and speech. The primary goal is to enhance the interactive capabilities of these models, allowing them to perceive, understand, and generate outputs across diverse inputs, just as a human would. These advancements are critical for creating more comprehensive AI systems to engage in natural interactions, respond to visual cues, interpret vocal instructions, and provide coherent responses in text and speech formats. Such a feat involves designing models to manage high-level cognitive tasks while integrating sensory and textual information.
Despite progress in individual modalities, existing AI models need help integrating vision and speech abilities into a unified framework. Current models are either vision-language or speech-language-focused, often failing to achieve a seamless end-to-end understanding of all three modalities simultaneously. This limitation hinders their application in scenarios that demand real-time interactions, such as virtual assistants or autonomous robots. Further, current speech models depend heavily on external tools for generating vocal outputs, which introduces latency and restricts flexibility in speech style control. The challenge remains in designing a model that can overcome these barriers while maintaining high performance in understanding and generating multimodal content.
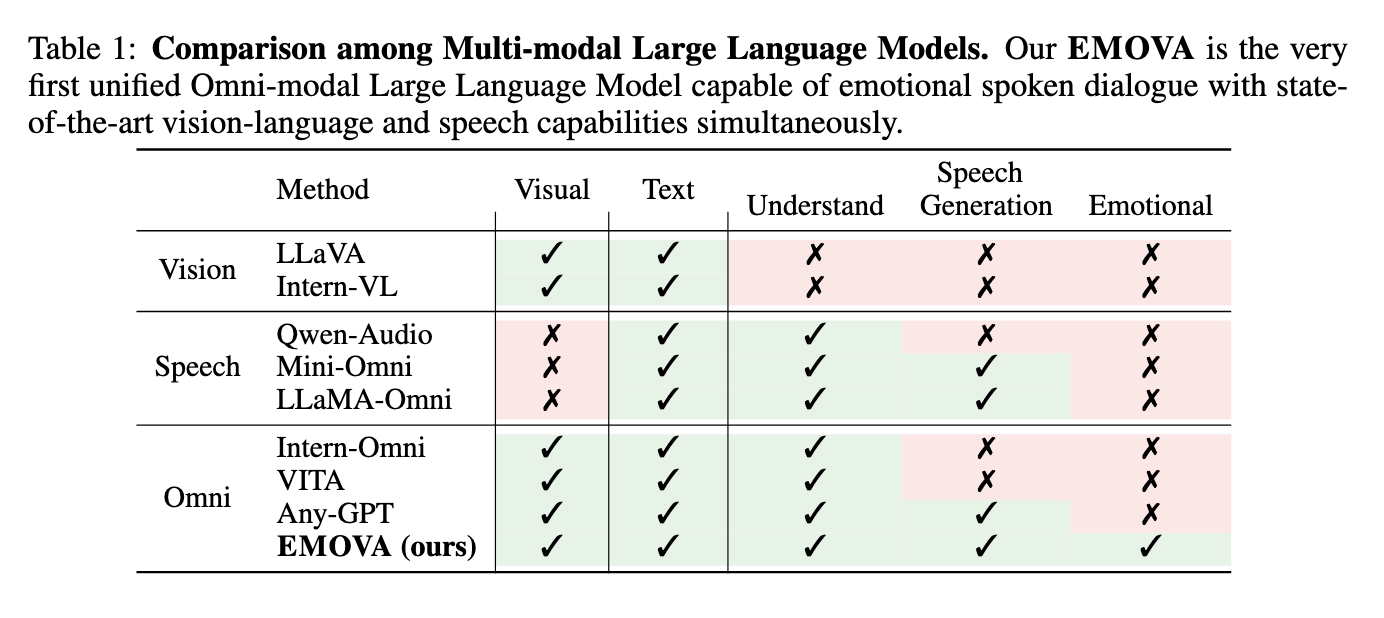
Several approaches have been adopted to improve multimodal models. Vision-language models like LLaVA and Intern-VL employ vision encoders to extract and integrate visual features with textual data. Speech-language models, such as Whisper, utilize speech encoders to extract continuous features, allowing the model to comprehend vocal inputs. However, these models are constrained by their reliance on external Text-to-Speech (TTS) tools for generating speech responses. This approach limits the model’s ability to generate speech in real-time and with an emotional variation. Moreover, attempts at omni-modal models, like AnyGPT, rely on discretizing data, which often results in information loss, especially in visual modalities, reducing the model’s effectiveness on high-resolution visual tasks.
Researchers from Hong Kong University of Science and Technology, The University of Hong Kong, Huawei Noah’s Ark Lab, The Chinese University of Hong Kong, Sun Yat-sen University and Southern University of Science and Technology have introduced EMOVA (Emotionally Omni-present Voice Assistant). This model represents a significant advancement in LLM research by seamlessly integrating vision, language, and speech capabilities. EMOVA’s unique architecture incorporates a continuous vision encoder and a speech-to-unit tokenizer, enabling the model to perform end-to-end processing of speech and visual inputs. By employing a semantic-acoustic disentangled speech tokenizer, EMOVA decouples the semantic content (what is being said) from the acoustic style (how it is said), allowing it to generate speech with various emotional tones. This feature is crucial for real-time spoken dialogue systems, where the ability to express emotions through speech adds depth to interactions.
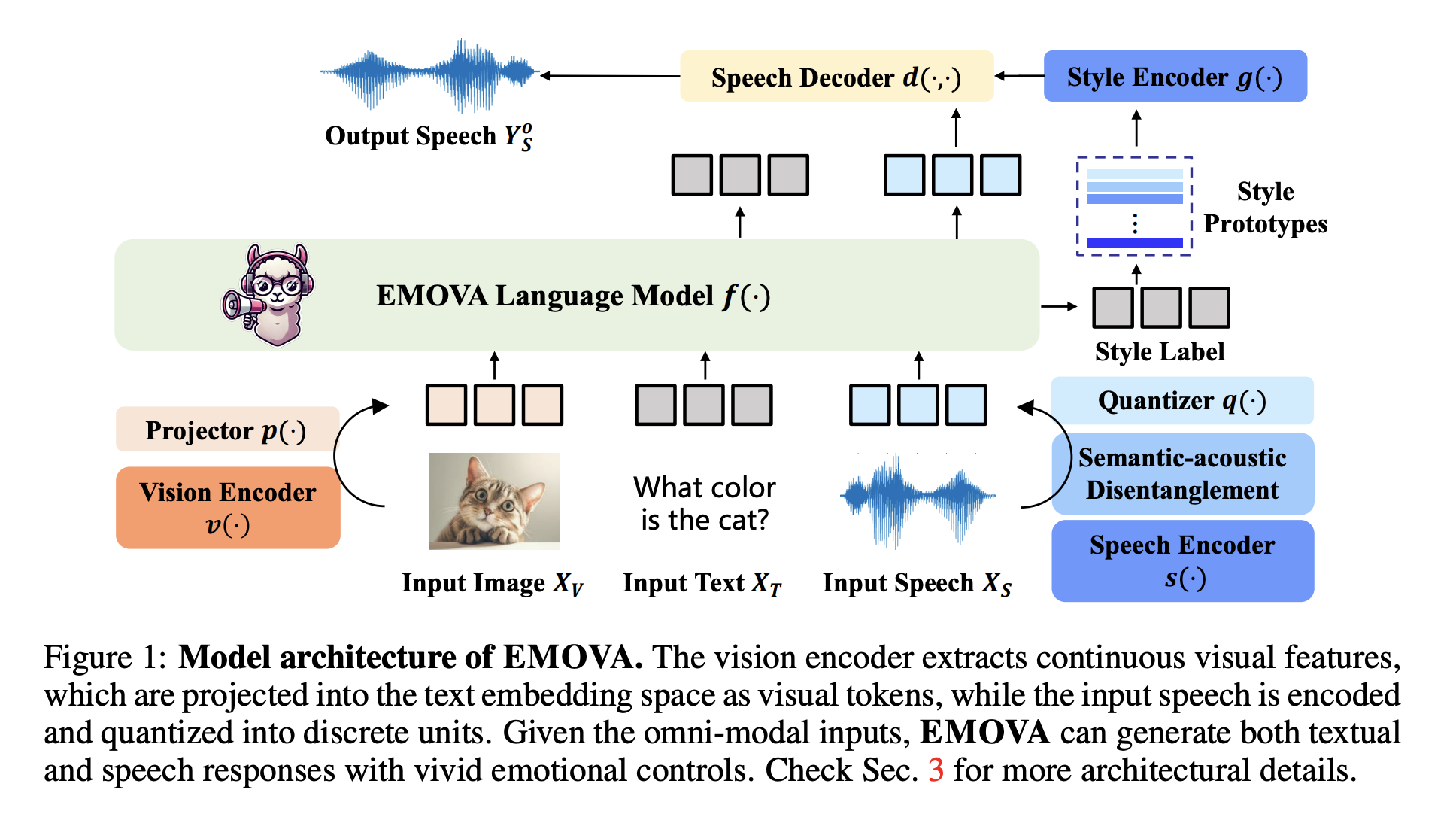
The EMOVA model comprises multiple components designed to handle specific modalities effectively. The vision encoder captures high-resolution visual features, projecting them into the text embedding space, while the speech encoder transforms speech into discrete units that the LLM can process. A critical aspect of the model is the semantic-acoustic disentanglement mechanism, which separates the meaning of the spoken content from its style attributes, such as pitch or emotional tone. This allows the researchers to introduce a lightweight style module for controlling speech outputs, making EMOVA capable of expressing diverse emotions and personalized speech styles. Furthermore, integrating the text modality as a bridge for aligning image and speech data eliminates the need for specialized omni-modal datasets, which are often difficult to obtain.
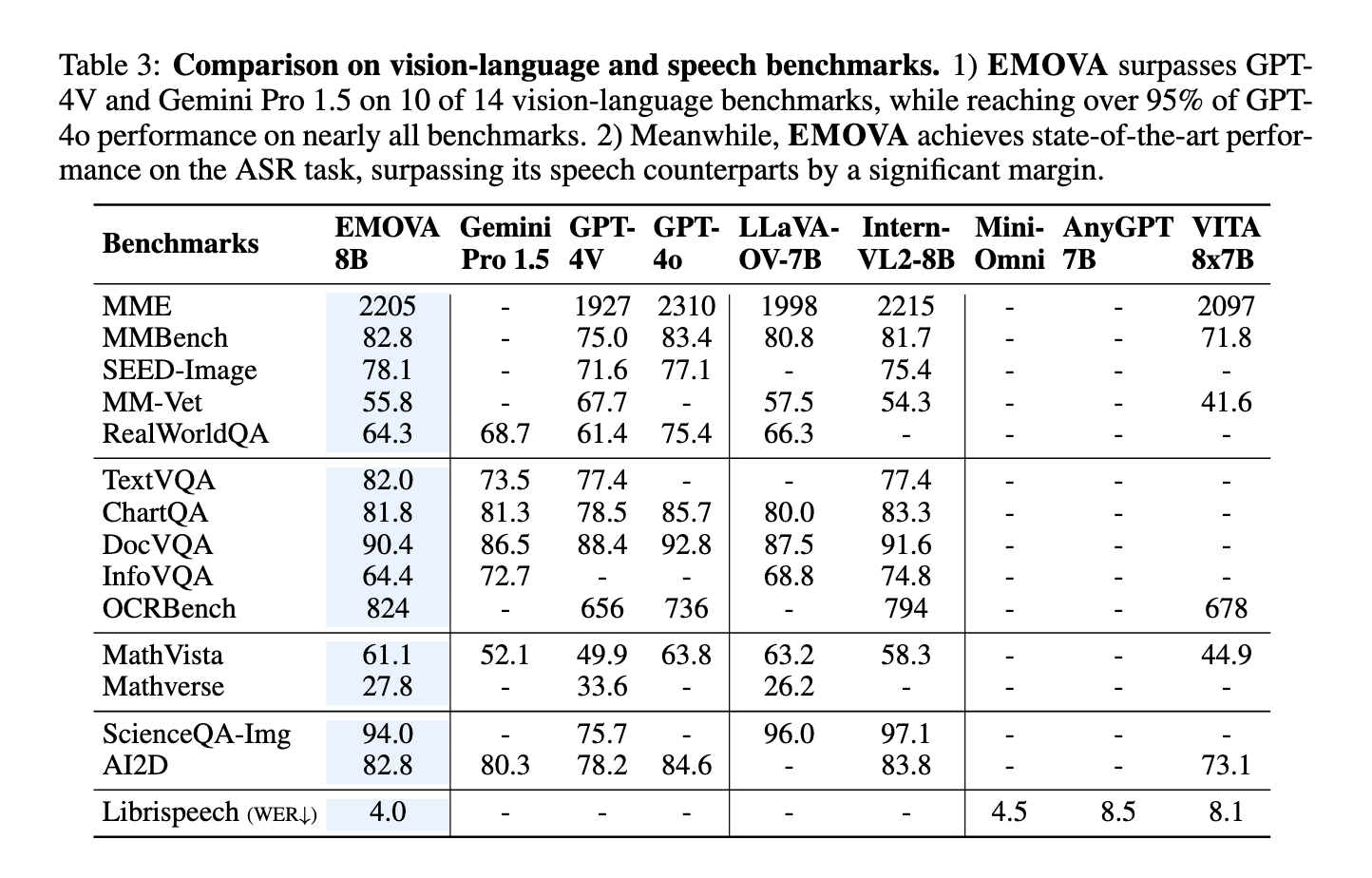
The performance of EMOVA has been evaluated on multiple benchmarks, demonstrating its superior capabilities in comparison to existing models. On speech-language tasks, EMOVA achieved a remarkable 97% accuracy, outperforming other state-of-the-art models like AnyGPT and Mini-Omni by a margin of 2.8%. In vision-language tasks, EMOVA scored 96% on the MathVision dataset, surpassing competing models like Intern-VL and LLaVA by 3.5%. Moreover, the model’s ability to maintain high accuracy in both speech and vision tasks simultaneously is unprecedented, as most existing models typically excel in one modality at the expense of the other. This comprehensive performance makes EMOVA the first LLM capable of supporting emotionally rich, real-time spoken dialogues while achieving state-of-the-art results across multiple domains.
In summary, EMOVA addresses a critical gap in the integration of vision, language, and speech capabilities within a single AI model. Through its innovative semantic-acoustic disentanglement and efficient omni-modal alignment strategy, it not only performs exceptionally well on standard benchmarks but also introduces flexibility in emotional speech control, making it a versatile tool for advanced AI interactions. This breakthrough paves the way for further research and development in omni-modal large language models, setting a new standard for future advancements in the field.
Check out the Paper and Project. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 50k+ ML SubReddit
Interested in promoting your company, product, service, or event to over 1 Million AI developers and researchers? Let’s collaborate!
Nikhil is an intern consultant at Marktechpost. He is pursuing an integrated dual degree in Materials at the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in Material Science, he is exploring new advancements and creating opportunities to contribute.